Los buscadores se dedican a recorrer todas las páginas web para así hacerse con la información que permite al usuario llegar hasta ellas con las búsquedas. Tenemos una pequeña forma de «controlar» como estos buscadores exploran nuestro sitio a través del archivo robots.txt, con el cual podemos desde decirle qué indexar hasta indicar lo que no queremos que tomen en cuenta de nuestro sitio.
WordPress es por supuesto un excelente gestor de contenidos. El único inconveniente que tiene es el mismo que todas las páginas y gestores de contenidos que existen, los buscadores. No nos confundamos, no es un inconveniente en sí, sino que dependiendo de qué buscadores realizen diferentes acciones en el sitio, puede ser beneficioso o perjudicial para este, y por tanto ahí es donde echamos mano del archivo robots.txt.
Lo primero que tenemos que tener en cuenta, es que no todos los buscadores lo toman en consideración (hay infinidad de buscadores que seguramente no conozcamos), y estos seguirán mirando nuestro sitio de la misma forma a no ser que los baneemos. Los grandes que son Google, Bing y Yahoo, además de algunos otros, sí que tienen en cuenta el archivo robots.txt y por tanto ahí es donde vamos a optimizarlo para que dé el mejor resultado en nuestro sitio.
La primera parte de la optimización, pasará por indicar a una buena cantidad de crawlers que no aportan absolutamente nada a nuestro sitio, que no deben entrar en él, ya que es una carga innecesaria de recursos. Algunos de ellos no harán caso del archivo pero aun así vamos a ponerlos por si acaso.
[default]User-agent: MSIECrawler
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: HTTrack
Disallow: /
User-agent: Microsoft.URL.Control
Disallow: /
User-agent: libwww
Disallow: /
User-agent: Orthogaffe
Disallow: /
User-agent: UbiCrawler
Disallow: /
User-agent: DOC
Disallow: /
User-agent: Zao
Disallow: /
User-agent: sitecheck.internetseer.com
Disallow: /
User-agent: Zealbot
Disallow: /
User-agent: MSIECrawler
Disallow: /
User-agent: SiteSnagger
Disallow: /
User-agent: WebStripper
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: Fetch
Disallow: /
User-agent: Offline Explorer
Disallow: /
User-agent: Teleport
Disallow: /
User-agent: TeleportPro
Disallow: /
User-agent: WebZIP
Disallow: /
User-agent: linko
Disallow: /
User-agent: HTTrack
Disallow: /
User-agent: Microsoft.URL.Control
Disallow: /
User-agent: Xenu
Disallow: /
User-agent: larbin
Disallow: /
User-agent: libwww
Disallow: /
User-agent: ZyBORG
Disallow: /
User-agent: Download Ninja
Disallow: /
User-agent: wget
Disallow: /
User-agent: grub-client
Disallow: /
User-agent: k2spider
Disallow: /
User-agent: NPBot
Disallow: /
User-agent: WebReaper
Disallow: /[/default]
Ahora que ya tenemos claro cómo se bloquean los crawlers, siempre podemos informarnos de algún otro y añadirlo, aunque esto ya depende de cada uno.
La frecuencia con la que un bot de un buscador revisa nuestro sitio es un tanto variable. Si bien hay herramientas como las Google Webmaster Tools para poder controlar incluso a qué horas quieres que indexe tu sitio, en el robots podemos indicarles a qué velocidad deberían indexar nuestro sitio dependiento tanto de la carga de nuestro servidor como de la cantidad de usuarios conectados que tengamos. Para ello utilizaremos el siguiente trozo de código para Google , Bing y Yahoo (slurp)
[default]User-agent: noxtrumbot
Crawl-delay: 50
User-agent: msnbot
Crawl-delay: 30
User-agent: Slurp
Crawl-delay: 10[/default]
Por supuesto podemos empezar poniendo frecuecias bajas e ir aumentando el número hasta que consigamos una velocidad óptima que no interfiera con nuestro sitio.
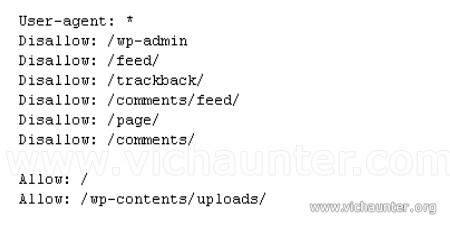
Ahora veremos una de las partes importantes. Nuestro sitio al tener una estructura determinada, veremos que hay varias carpetas en las que no es necesario que los robots se metan a buscar, por tanto podemos indicarles directamente en qué carpetas buscar y cuales no deben tener en cuenta con la siguiente parte del código:
[default]User-Agent: *
Allow: /wp-content/uploads/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-includes/
Disallow: /wp-admin/
Disallow: /wp-[/default]
Así evitaremos que entren en las carpetas sin contenido y con la última línea le indicamos que todos los archivos que empiezen por wp- no son relevantes y no es necesario que los intenten cargar.
Esta parte queda a criterio de cada uno, ya que es un tanto impreciso el que google lo tome como contenido duplicado o no. En las páginas de búsqueda normalmente el contenido que aparece es el mismo que en otras partes del sitio, por tanto no nos interesa que google se ponga a buscar.
[default]Disallow: /?s=
Disallow: /search[/default]
Casi terminamos, ahora revisaremos las hojas rss (feeds). En este caso, ya que su finalidad es que los usuarios tengan las últimas noticias en sus lectores de rss y no que google las indexe (para eso tiene las páginas del sitio), lo que haremos de todas formas será indicarle que puede coger la hoja principal de noticias, pero no debe mirar ni las hojas de comentarios, ni de trackbacks, ni otras que lo único que harán será solapar los resultados de nuestro sitio, consiguiendo confundir a los usuarios que lleguen mediante esos enlaces.
[default]Allow: /feed/$
Disallow: /feed
Disallow: /comments/feed
Disallow: /*/feed/$
Disallow: /*/feed/rss/$
Disallow: /*/trackback/$
Disallow: /*/*/feed/$
Disallow: /*/*/feed/rss/$
Disallow: /*/*/trackback/$
Disallow: /*/*/*/feed/$
Disallow: /*/*/*/feed/rss/$
Disallow: /*/*/*/trackback/$[default]
Por último lo que vamos a hacer es, para los crawlers despistados, o por si hemos creado una ruta diferente a la normal, indicar dónde tenemos el sitemap en nuestra web. Así los buscadores lo encontrarán aunque no tengamos otras herramientas donde subir los xml para que los indexen.
[default]Sitemap: http://www.dominio.com/sitemap.xml[/default]
Por supuesto cambiaremos www.dominio.com por nuestro dominio, o la url completa por la que tengamos nosotros.
Como puede resultar algo lioso el haberlo explicado por partes a la hora de unirlo todo en un único archivo, vamos a ver ahora mismo el código entero que podemos colocar en nuestro robots.txt
[default]
User-agent: MSIECrawler
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: HTTrack
Disallow: /
User-agent: Microsoft.URL.Control
Disallow: /
User-agent: libwww
Disallow: /
User-agent: Orthogaffe
Disallow: /
User-agent: UbiCrawler
Disallow: /
User-agent: DOC
Disallow: /
User-agent: Zao
Disallow: /
User-agent: sitecheck.internetseer.com
Disallow: /
User-agent: Zealbot
Disallow: /
User-agent: MSIECrawler
Disallow: /
User-agent: SiteSnagger
Disallow: /
User-agent: WebStripper
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: Fetch
Disallow: /
User-agent: Offline Explorer
Disallow: /
User-agent: Teleport
Disallow: /
User-agent: TeleportPro
Disallow: /
User-agent: WebZIP
Disallow: /
User-agent: linko
Disallow: /
User-agent: HTTrack
Disallow: /
User-agent: Microsoft.URL.Control
Disallow: /
User-agent: Xenu
Disallow: /
User-agent: larbin
Disallow: /
User-agent: libwww
Disallow: /
User-agent: ZyBORG
Disallow: /
User-agent: Download Ninja
Disallow: /
User-agent: wget
Disallow: /
User-agent: grub-client
Disallow: /
User-agent: k2spider
Disallow: /
User-agent: NPBot
Disallow: /
User-agent: WebReaper
Disallow: /
User-agent: noxtrumbot
Crawl-delay: 40
User-agent: msnbot
Crawl-delay: 20
User-agent: Slurp
Crawl-delay: 10
User-Agent: *
Allow: /wp-content/uploads/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-includes/
Disallow: /wp-admin/
Disallow: /wp-
Disallow: /?s=
Disallow: /search
Allow: /feed/$
Disallow: /feed
Disallow: /comments/feed
Disallow: /*/feed/$
Disallow: /*/feed/rss/$
Disallow: /*/trackback/$
Disallow: /*/*/feed/$
Disallow: /*/*/feed/rss/$
Disallow: /*/*/trackback/$
Disallow: /*/*/*/feed/$
Disallow: /*/*/*/feed/rss/$
Disallow: /*/*/*/trackback/$
Sitemap: http://tu-web/sitemap.xml
[/default]
Hemos de tener en cuenta que cada uno es responsable de poner o no este contenido en su sitio. Aquí hemos comprobado que funciona pero no nos hacemos responsables de los efectos que pueden tener en según que sitios.
Si tienes alguna duda o sugerencia no dudes en dejar un comentario